🌍 Привет мир! 👋🏻
🌍 Привет мир! 👋🏻
Продолжаем двигаться в сторону понимания AI, уже поговорили про Vector DB, следующее что на слуху когда речь заходит про AI - это Retrieval-Augmented Generation (RAG).
❓ Какую проблему решает RAG
В больших языковых моделях (БЯМ) ответы генерируются на основе предварительно изученных шаблонов и информации на этапе обучения.
✏️ Пример:
Вопрос: На сколько актуальна база у модели ChatGPT 4o ?
Ответ: Моя база знаний обучена на данных до июня 2024 года.
Более того, некоторые модели ограничены данными, на которых они были обучены, что часто приводит к ответам, которым может не хватать глубины или конкретных знаний.
И тут на помощь 🚨 приходит RAG, который использует данные из внешних источников для дополнения вашего запроса, устраняя указанные выше ограничения.
⁉️ Как работает RAG
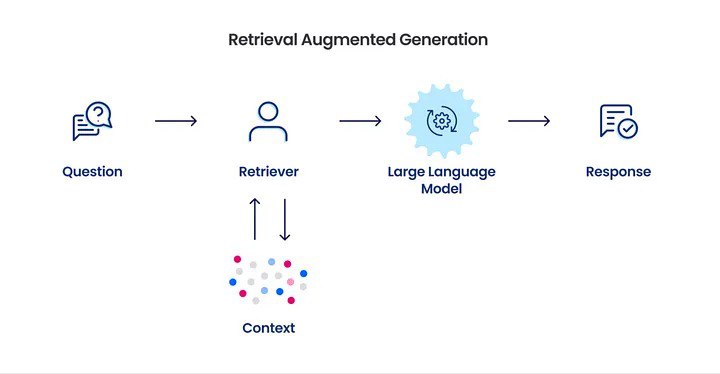
1️⃣ Пользователь вводит свой вопрос или промпт.
2️⃣ Запрос уходит в Retriever, который ищет релевантные документы или части информации, с помощью которых в последующем сформируется полноценный ответ от БЯМ. На выходе из ретривера мы получем context.
3️⃣ Сформированный context и user query передается в БЯМ, за счет контекста мы получаем более точный и детализированный ответ, так как response формируется не только за счет уже имеющихся знаний, но и дополняется (Augmented) конкретными подробностями из извлеченного context.
📝 Типы Retrievers
Retriever – это компонент в RAG, который занимается поиском 🔎 и извлечением 📤 релевантной информации.
📎 Sparse Retriever - поиск по ключевым словам.
➖ Основан на методах сопоставления терминов, таких как TF-IDF или BM25.
❓ Как работает
1. Квери пользователя остаётся в текстовом виде.
2. Поиск идёт по индексированным текстам в базе данных (например, Elasticsearch).
3. Находятся документы 📑 с наибольшим совпадением ключевых слов.
✏️ Пример:
Запрос: "Как работает микроволновка?"
Происходит поиск документов, которые содержат слова "микроволновка", "работает", и возвращает их по степени релевантности.
📎 Dense Retriever - поиск по векторным представлениям.
➖ Использует векторные представления текста.
❓ Как работает
1. Квери пользователя превращается в вектор.
2. Вектор сравнивается с векторами документов в базе данных (например, Chroma, Weaviate...).
3. Возвращаются документы с наибольшей схожестью.
✏️ Пример:
Запрос: "Как работает микроволновка?"
1️⃣ Запрос превращается в вектор (например,
2️⃣ Поиск идёт среди документов, у которых похожие векторные представления.
3️⃣ Находится документ "Инструкция микроволновки...", даже если там нет точного совпадения слов.
📎 Hybrid Retriever - гибридный поиск
➖ Комбинирует Sparse Retriever и Dense Retriever.
➖ Используется для улучшения качества поиска.
🚀 Типы контекста который формирует Retriever?
👉🏻 Структурированный - организованный набор данных, например JSON.
👉🏻 Неструктурированный - обычный текст из статей, документов, чатов.
👉🏻 Векторный - представляет информацию в виде векторов.
❓ Где применяется RAG
RAG применяют везде, где нужно точное и актуальное извлечение данных + генерация осмысленных ответов (медицина, юриспруденция, финансы и др.) .
👎🏻 Недостатки RAG
1️⃣ Зависимость от качества поиска - если поиск извлекает нерелевантные или устаревшие данные, ответ модели будет неточным, модель может придумывать (галлюцинировать) ответы.
2️⃣ Снижается скорость - RAG требует выполнения поиска + генерации, что делает его медленнее, чем обычные LLM-ответы.
3️⃣ Ограниченный контекст - у LLM есть лимит на длину контекста, поэтому длинные документы могут усекаться или обрабатываться не полностью.
💬 Делитесь своим мнением в комментариях👇! Если вам понравилась статья, не забудьте поставить лайк! 👍
#AI
Продолжаем двигаться в сторону понимания AI, уже поговорили про Vector DB, следующее что на слуху когда речь заходит про AI - это Retrieval-Augmented Generation (RAG).
❓ Какую проблему решает RAG
В больших языковых моделях (БЯМ) ответы генерируются на основе предварительно изученных шаблонов и информации на этапе обучения.
✏️ Пример:
Вопрос: На сколько актуальна база у модели ChatGPT 4o ?
Ответ: Моя база знаний обучена на данных до июня 2024 года.
Более того, некоторые модели ограничены данными, на которых они были обучены, что часто приводит к ответам, которым может не хватать глубины или конкретных знаний.
И тут на помощь 🚨 приходит RAG, который использует данные из внешних источников для дополнения вашего запроса, устраняя указанные выше ограничения.
⁉️ Как работает RAG
1️⃣ Пользователь вводит свой вопрос или промпт.
2️⃣ Запрос уходит в Retriever, который ищет релевантные документы или части информации, с помощью которых в последующем сформируется полноценный ответ от БЯМ. На выходе из ретривера мы получем context.
3️⃣ Сформированный context и user query передается в БЯМ, за счет контекста мы получаем более точный и детализированный ответ, так как response формируется не только за счет уже имеющихся знаний, но и дополняется (Augmented) конкретными подробностями из извлеченного context.
📝 Типы Retrievers
Retriever – это компонент в RAG, который занимается поиском 🔎 и извлечением 📤 релевантной информации.
📎 Sparse Retriever - поиск по ключевым словам.
➖ Основан на методах сопоставления терминов, таких как TF-IDF или BM25.
❓ Как работает
1. Квери пользователя остаётся в текстовом виде.
2. Поиск идёт по индексированным текстам в базе данных (например, Elasticsearch).
3. Находятся документы 📑 с наибольшим совпадением ключевых слов.
✏️ Пример:
Запрос: "Как работает микроволновка?"
Происходит поиск документов, которые содержат слова "микроволновка", "работает", и возвращает их по степени релевантности.
📎 Dense Retriever - поиск по векторным представлениям.
➖ Использует векторные представления текста.
❓ Как работает
1. Квери пользователя превращается в вектор.
2. Вектор сравнивается с векторами документов в базе данных (например, Chroma, Weaviate...).
3. Возвращаются документы с наибольшей схожестью.
✏️ Пример:
Запрос: "Как работает микроволновка?"
1️⃣ Запрос превращается в вектор (например,
[-0.12, 0.58, ...]).2️⃣ Поиск идёт среди документов, у которых похожие векторные представления.
3️⃣ Находится документ "Инструкция микроволновки...", даже если там нет точного совпадения слов.
📎 Hybrid Retriever - гибридный поиск
➖ Комбинирует Sparse Retriever и Dense Retriever.
➖ Используется для улучшения качества поиска.
🚀 Типы контекста который формирует Retriever?
👉🏻 Структурированный - организованный набор данных, например JSON.
👉🏻 Неструктурированный - обычный текст из статей, документов, чатов.
👉🏻 Векторный - представляет информацию в виде векторов.
❓ Где применяется RAG
RAG применяют везде, где нужно точное и актуальное извлечение данных + генерация осмысленных ответов (медицина, юриспруденция, финансы и др.) .
👎🏻 Недостатки RAG
1️⃣ Зависимость от качества поиска - если поиск извлекает нерелевантные или устаревшие данные, ответ модели будет неточным, модель может придумывать (галлюцинировать) ответы.
2️⃣ Снижается скорость - RAG требует выполнения поиска + генерации, что делает его медленнее, чем обычные LLM-ответы.
3️⃣ Ограниченный контекст - у LLM есть лимит на длину контекста, поэтому длинные документы могут усекаться или обрабатываться не полностью.
💬 Делитесь своим мнением в комментариях👇! Если вам понравилась статья, не забудьте поставить лайк! 👍
#AI
Хотите больше таких постов?
Подпишитесь на канал и читайте продолжение в Telegram.